AMD AI 9 HX 370 16Cu核显性能对比与分析
自从AMD Zen架构登陆移动端后,其锐龙4000、锐龙5000系列中的Vega核显、锐龙6000、7000、8000系列中的RDNA 2/RDNA 3架构核显凭借着同时代下优秀的实际性能表现和终端产品上更高的性价比,“核显”成为了一直以来大家关注AMD锐龙处理器时的焦点,也是不少人选择AMD锐龙处理器的重要原因之一。
本代的AI 300系列处理器在核显方面有着较大的升级,旗舰型号AI 9 HX 370中的核显代号改为了Radeon 890M,架构由前两代的RDNA 3升级为了RDNA 3.5,规格也从12Cu升级到了16Cu,升级幅度着实不小,那么它的性能如何?和独立显卡比又如何呢?
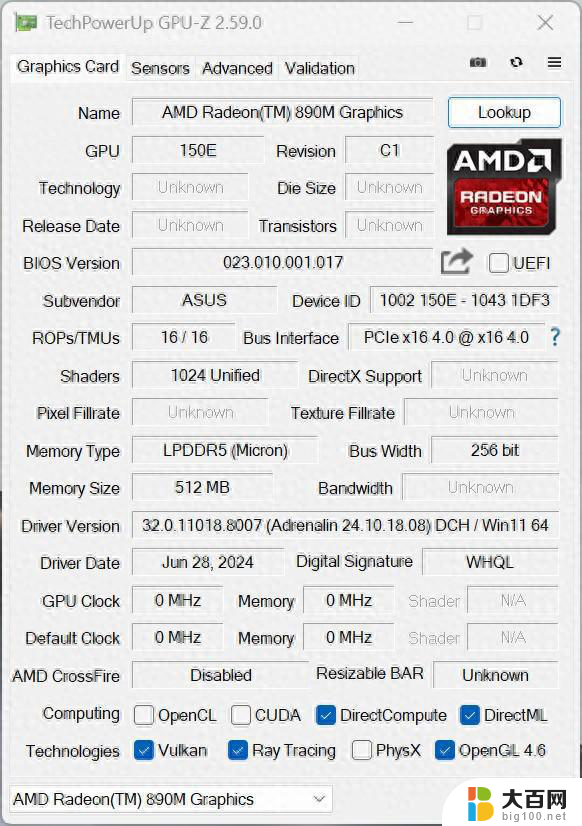
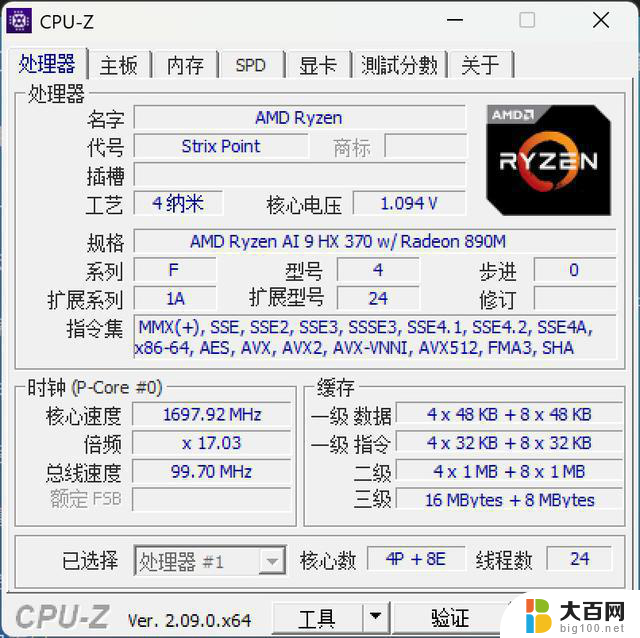
CPU部分,Strix Point也有较大程度的革新,使用到了同架构大小核的设计,旗舰型号AI 9 HX 370共拥有4个Zen5大核+8个Zen5c小核心,24线程,AMD锐龙在消费级首个将被大面积搭载的大小核心架构处理器表现又是怎样的呢?
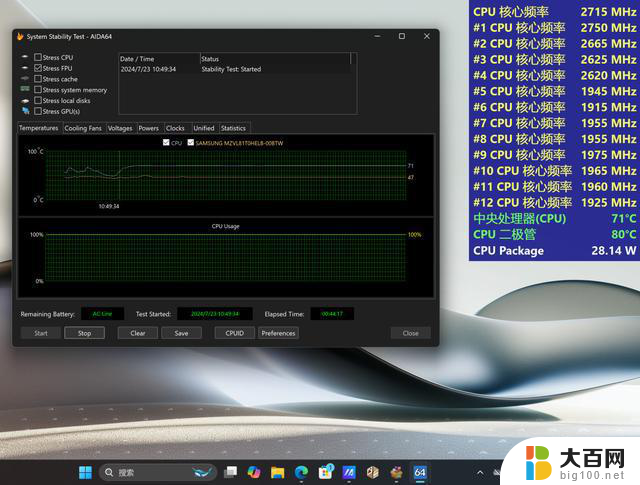
本次用来测试AI 9 HX 370的机型定位是高端轻薄本,主打的是高阶质感+静音体验,Stress FPU单烤时的功耗为28W,风扇噪音非常安静,并不是目前市面上主流级轻薄本的性能释放水平,所以这台产品中的AI 9 HX 370,性能表现可以被视为一个比较基础的成绩,在大部分性能释放更高的机型中,无论理论性能还是实际表现肯定会比它更好一些。
一、AI 9 HX 370核显部分
首先来看下Radeon 890M在3DMARK中的性能表现,代表DX11性能的Fire Strike Extreme得分4205分,代表DX12性能的Time Spy得分3275分。
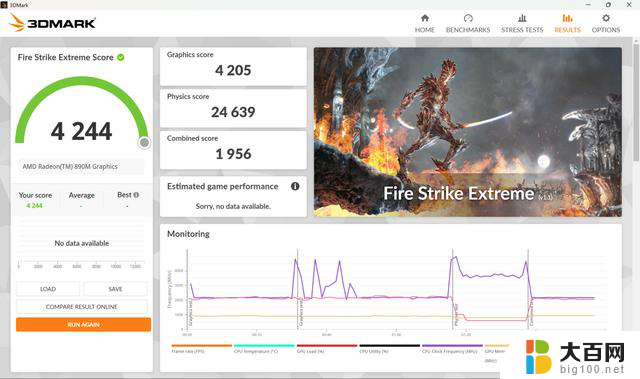
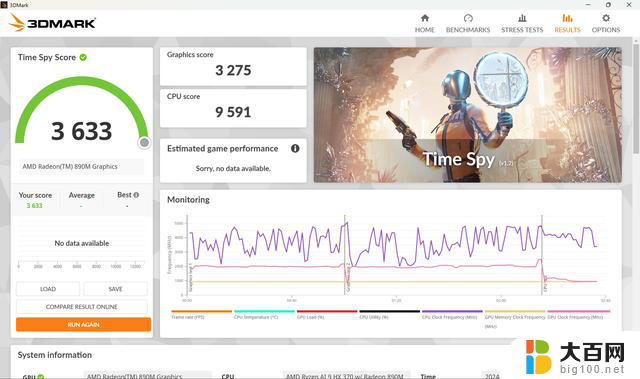
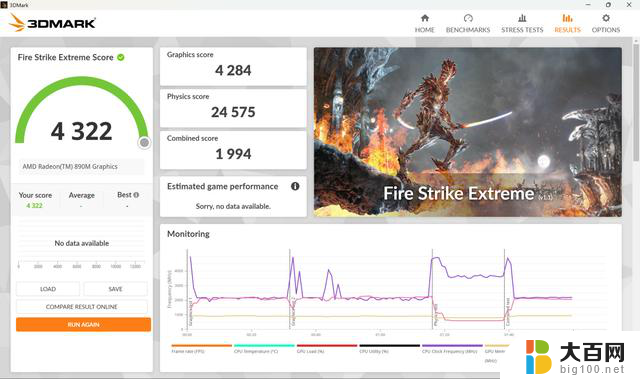
另外,测试机型具备手动分配显存的功能,可手动分配1GB、2GB、4GB和8GB的显存,在分配了8GB显存后,Fire Strike Extreme得分4284分,Time Spy得分3489分。
以Time Spy的得分为例,先来看看Radeon 890M相比于上代的Radeon 780M有多大的提升。
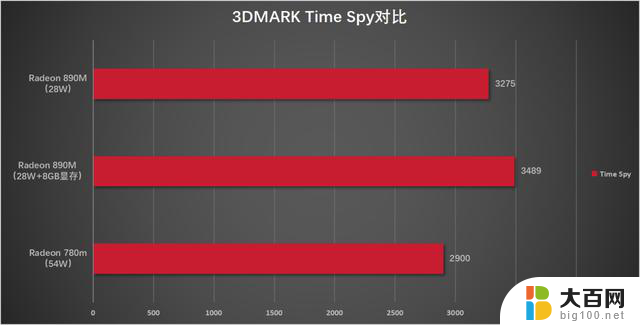
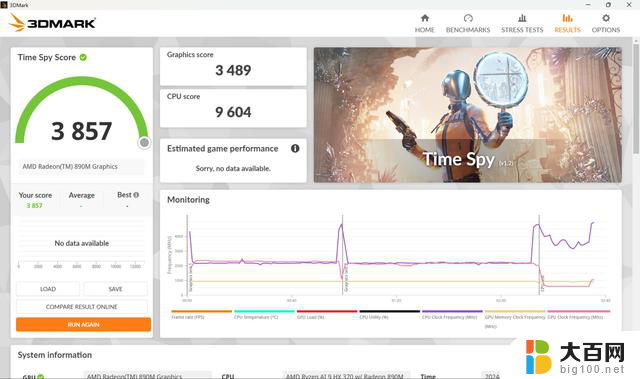
测试机型中的内存频率为LPDDR5 7500MHz;对比搭载了R7 7840HS的机型,内存频率为LPDDR5 6400MHz,单烤Stress FPU性能释放54W,在这种情况下Radeon 780M的Time Spy跑分大致为2900分左右,也就是说在功耗差距接近一倍的情况下,Radeon 890M相比于Radeon 780M就已经有了13%~20%左右的性能提升,而如果是同样在功耗释放比较宽泛的机型中,Radeon 890M的Time Spy跑分能够达到3700~3800的水平,提升幅度会达到27.5%~30%左右,很接近从12Cu提升到16Cu三分之一的规格提升了。
不过,Radeon 890M可不仅仅是规格提升了,架构也升级了呀,虽然并不是从RDNA “3”提升到RDNA “4”的代际提升,但是RDNA “3.5”怎么也算半代的升级啊,再加上增多了三分之一的核心数量,怎么看都应该是至少33%往上的性能提升,可实际的性能表现和预期存在一定的距离,这是怎么一回事呢?

这是由于内存带宽喂不饱Radeon 890M的高规格核显,虽然LPDDR5x 7500MHz的内存已经是相当可观了,但是对于“显存”来说,双通道LPDDR5x 7500MHz还是不太富裕的,远没有独显上的GDDR6/GDDR6x显存来的猛,Radeon 890M上面又没有AMD Infinity Cache,所以内存成为了Radeon 890M的瓶颈,造成了它的性能表现并没有预期来的那么强,这也很好的说明了为什么在手动分配显存后,拥有了专用显存的Radeon 890M在Time Spy中会有一定的性能提升了——Radeon 890M获得了一部分只可以自己取用的内存,而不是与CPU共享。
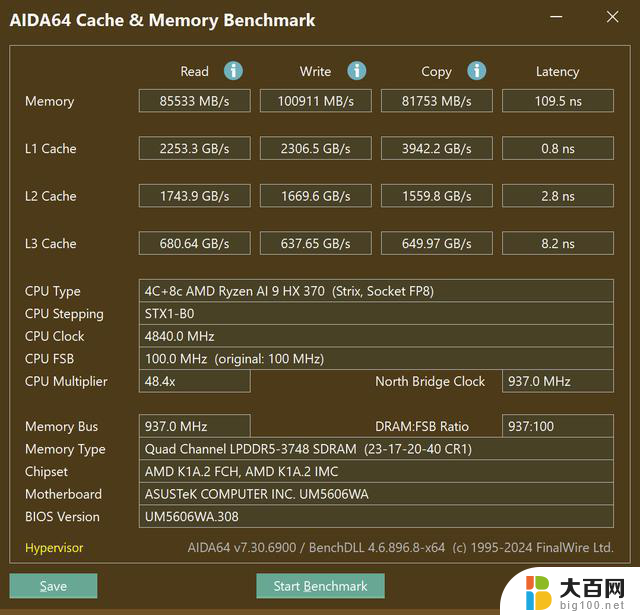
LPDDR5-7500MHz 内存带宽/延迟测试
反映到实际游戏上面,如果是在本身就对于CPU和内存带宽要求比较高的游戏中,例如PUBG,那么Radeon 890M与CPU互抢内存带宽的情况就会加剧,更加吃不饱的Radeon 890M帧数表现与上一代的Radeon 780M差距就会更被缩进了。
由于我拿到机子之后测试时间有限,只来得及测试了两款3A游戏,分别为《古墓丽影:暗影》与《赛博朋克2077》
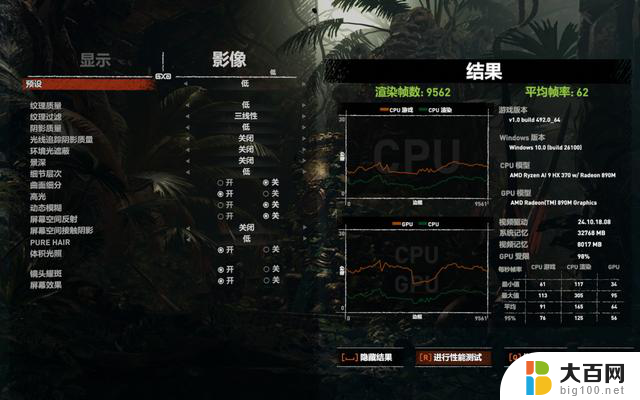
在《古墓丽影:暗影》中,1080P低画质,运行游戏内的BenchMark:
显存自动:平均帧61;
分配8GB显存后:平均帧62。

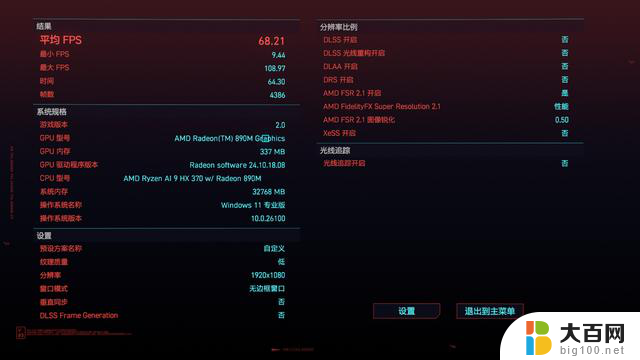
在赛博朋克2077中,1080P低画质,打开AMD FSR 2.1至性能档位,运行游戏内的BenchMark:
显存自动:平均帧68.21帧;
分配8GB显存后:平均帧68.93帧。
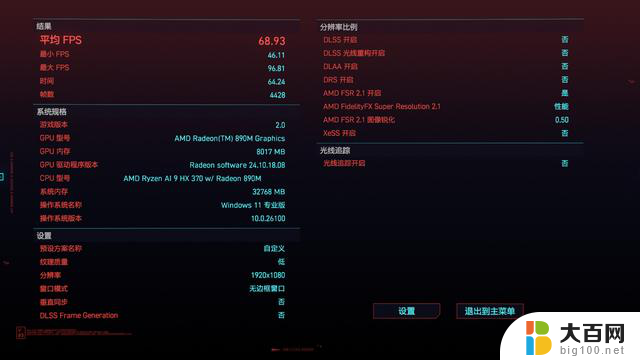
在大部分3A游戏中,压力基本都集中在GPU而不是CPU,所以在这两款3A游戏中我们并没有看到在手动分配专用显存后,Radeon 890M有什么帧数上面的差距。两款游戏的帧数就权当是给大家做一个参考了。
接着我们再来看看Radeon 890M的Time Spy跑分能够与哪几款移动端的独立显卡进行比较,直接看图:
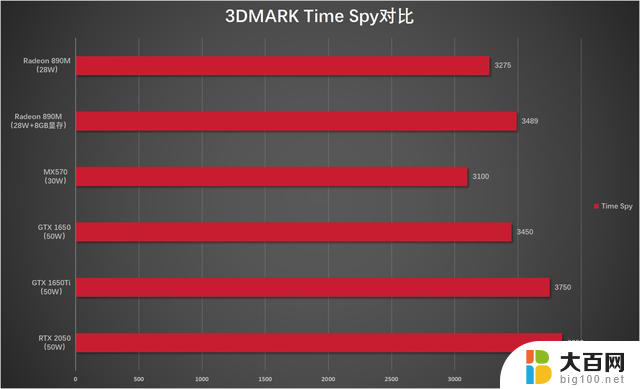
移动端的GTX 1650在50W功耗下,Time Spy得分3450分左右;50W的1650Ti Time Spy跑分在3750分左右;50W的RTX 2050得分在3850分左右;末代MX系列旗舰MX570在30W时Time Spy在3100分左右。
从Time Spy的跑分来看,Radeon 890M的性能表现在28W时就已经可以齐平GTX 1650了,超出了MX570;而如果是在高功耗的机型中,Radeon 890M可以达到GTX 1650Ti或者RTX 2050的性能,基本和NVIDIA图灵架构、安培架构的入门级独显相当了。
二、AI 9 HX 370 CPU部分
当然各种场景下并不能光看显卡,处理器也是至关重要的,Strix Point这次在CPU部分也进行了革新,采用了大小核设计,不过与英特尔的异构大小核不同的是,Strix Point为同架构大小核心,具体到AI 9 HX 370上,共4个Zen5大核心(最大睿频5.1GHz)+8个Zen5c小核心(最大睿频3.3GHz),均支持超线程,4个Zen5核心为一个CCX,8个Zen5c核心为一个CCX。其中4个Zen5大核心共享16MB L3缓存,8个Zen5c小核心共享8MB L3缓存,每个Zen5/Zen5c核心均提供1MB L2缓存。

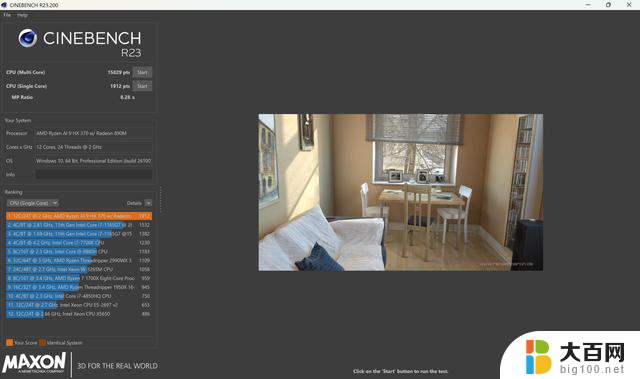
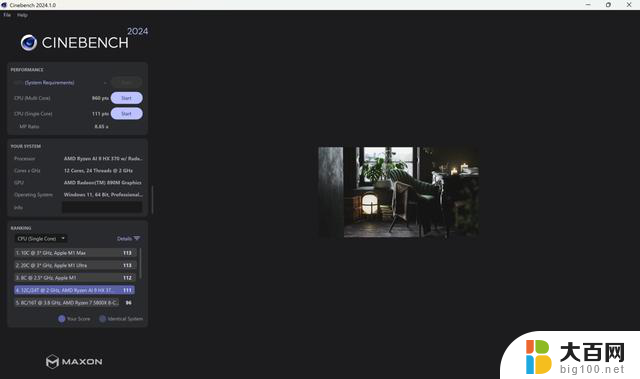
这样的架构设计显然会提供更强的多核心性能,毕竟拥有高达12个支持超线程的核心,在CINEBENCH R23和CINEBENCH 2024中,多核成绩分别为17451分和960分(同样的,这是28W性能释放的表现)。
单核方面在Zen5架构的支持下同样有不小的提升,CINEBENCH R23和CINEBENCH 2024中的单核成绩分别为1909分和111分。
如果您是专业软件用户,那么恭喜您,全新的AI 300系列处理器很有可能让您享受到更好的性能表现,两个CCX之间的核心延迟、8个Zen5c核心过小的L3缓存都不怎么会影响到这方面的性能表现,完全可以吃到大小核架构提供的多核性能红利。
而如果您在寻求游戏表现或所需应用对缓存与内存带宽比较敏感,那么核心占用在4个以内的游戏或应用,通过手动限制跑在4个Zen5大核上则会有更好的表现,而如果说核心占用需要大于4个核心,那么8个Zen5c过小的共享缓存以及两个CCX之间的核心访问延迟,则会拖累性能表现。所以如果是比较喜欢折腾的朋友,对自己经常使用的应用或经常玩的游戏手动限制一下负载核心,然后前后对比一下,可能能够寻求到更好的性能表现,毕竟大小核心的调度问题,从12代酷睿开始就用上大小核的英特尔也不能说是整明白了,这是老大难问题了,也不能过于苛求AMD一上来就做得很好。
三、写在最后
虽然本篇文章几乎一半都在“唱衰”Strix Point,指出它身上存在的一些问题,但是不可置否的是,其CPU性能和核显性能在绝大多数场景下,依然是是当下最好的选择之一,无论对比上代还是来自隔壁同样为旗舰级处理器的竞争对手,它都能够提供更好的性能表现。

而本代AI 300中需要改进的点也非常的显而易见,规格出众的核显由于内存带宽问题在部分场景中性能受限、双CCX之间核心访问延迟较大、Zen5c核心共享的L3缓存过小、大小核心的优化与调度需要继续精进。这四个问题相信也是接下来40Cu的Strix Halo(不过它是全大核心设计,并没有采用大小核心设计)以及后续迭代产品中需要AMD重点解决与优化的对象,希望我们在之后可以看到补足短板后的AMD锐龙产品吧!
AMD AI 9 HX 370 16Cu核显性能对比与分析相关教程
- 铭瑄显卡性能评测与用户反馈分析:最全面的显卡性能分析报告
- 4090显卡与7900XTX显卡性能对比:究竟哪个才是真正的性能王者?
- AMD RX 7900M显卡跑分首次曝光 仍不敌RTX 4090,性能对比惊人!
- 揭秘2024显卡天梯:性价比与性能的终极对决!你需要知道的最全面信息
- 懂显卡参数及 2024 显卡天梯图,全面了解显卡性能对比
- AMD R7 8700F和R5 8400F无核显版性能解析:究竟是无脑入手还是理性购买?
- AMD刚刚开卖桌面最强核显新U,发现忘把性能锁打开了,为什么这个错误会对性能产生影响?
- win10运行速度比win7快吗 win10和win7性能对比
- AMD放CPU能让Instinct MI300A APU打败GPU吗?解析与比较
- GTX 1060显卡性能评测:值得购买吗?价格性价比如何?
- 国产CPU厂商的未来较量:谁将主宰中国处理器市场?
- 显卡怎么设置才能提升游戏性能与画质:详细教程
- AMD,生产力的王者,到底选Intel还是AMD?心中已有答案
- 卸载NVIDIA驱动后会出现哪些问题和影响?解析及解决方案
- Windows的正确发音及其读音技巧解析:如何准确地发音Windows?
- 微软总裁:没去过中国的人,会误认为中国技术落后,实际情况是如何?
微软资讯推荐
- 1 显卡怎么设置才能提升游戏性能与画质:详细教程
- 2 ChatGPT桌面版:支持拍照识别和语音交流,微软Windows应用登陆
- 3 微软CEO称别做井底之蛙,中国科技不落后西方使人惊讶
- 4 如何全面评估显卡配置的性能与适用性?快速了解显卡性能评估方法
- 5 AMD宣布全球裁员4%!如何影响公司未来业务发展?
- 6 Windows 11:好用与否的深度探讨,值得升级吗?
- 7 Windows 11新功能曝光:引入PC能耗图表更直观,帮助用户更好地监控电脑能耗
- 8 2024年双十一七彩虹显卡选购攻略:光追DLSS加持,畅玩黑悟空
- 9 NVIDIA招聘EMC工程师,共同推动未来技术发展
- 10 Intel还是AMD游戏玩家怎么选 我来教你双11怎么选CPU:如何在双11选购适合游戏的处理器
win10系统推荐
系统教程推荐
- 1 win11文件批给所有权限 Win11共享文件夹操作详解
- 2 怎么清理win11更新文件 Win11清理Windows更新文件的实用技巧
- 3 win11内核隔离没有了 Win11 24H2版内存隔离功能怎么启用
- 4 win11浏览器不显示部分图片 Win11 24H2升级后图片无法打开怎么办
- 5 win11计算机如何添加常用文件夹 Win11文件夹共享的详细指南
- 6 win11管理应用权限 Win11/10以管理员身份运行程序的方法
- 7 win11文件夹内打开图片无预留 Win11 24H2升级后图片无法打开怎么办
- 8 win11访问另外一台电脑的共享文件夹 Win11轻松分享文件的方法
- 9 win11如何把通知关闭栏取消 win11右下角消息栏关闭步骤
- 10 win11安装更新0x800f081f Win11 23H2更新遇到错误代码0x800f081f怎么处理