微软提示工程开创新纪元:GPT-4成为医学专家,超越其他高度微调模型!
西风 发自 凹非寺
量子位 | 公众号 QbitAI
微软最新研究再次证明提示工程的威力——
无需额外微调,无需专家策划,仅凭提示,GPT-4就能化身“专家”。

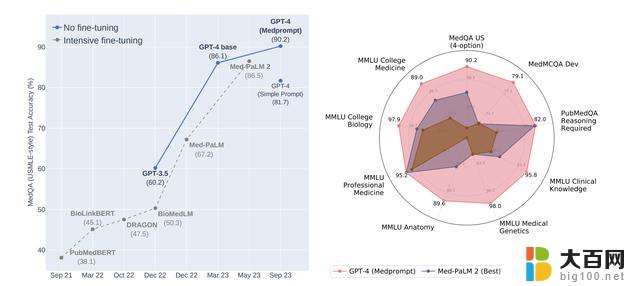
使用他们提出的最新提示策略Medprompt,在医疗专业领域,GPT-4在MultiMed QA九个测试集中取得最优结果。
在MedQA数据集(美国医师执照考试题)上,Medprompt让GPT-4的准确率首次超过90%,超越BioGPT和Med-PaLM等一众微调方法。
研究人员还表示Medprompt方法是通用的,不仅适用于医学,还可以推广到电气工程、机器学习、法律等专业中。
这项研究在X(原Twitter)一经分享,就引发众多网友关注。
沃顿商学院教授Ethan Mollick、Artificial Intuition作者Carlos E. Perez等都有转发分享。
Carlos E. Perez直呼“出色的提示策略可以甩微调一大截”:
有网友表示早就有这种预感,现在能看到结果出来。真的是“so cool”:

还有网友表示这真的很“激进”:
 组合提示策略,“变身”专家
组合提示策略,“变身”专家Medprompt是多种提示策略的组合体,包含三大法宝:
动态少样本选择(Dynamic few-shot selection)自生成思维链(Self-generated chain of thought)选项洗牌集成(Choice shuffling ensemble)
下面我们来一一介绍。
 动态少样本选择
动态少样本选择少样本学习可以说是让模型快速学习上下文的一种最有效的方法。简单来说,就是输入一些示例,让模型快速适应特定领域,并学习遵循任务的格式。
这种用于特定任务提示的少样本示例通常是固定的,所以对示例的代表性和广泛性有较高的要求。
之前一种方法是让领域专家手动制作范例,但即便如此,也不能保证专家策划的固定的少样本示例在每个任务中都有代表性。
因此,微软研究人员提出了动态少样本示例的方法。
想法是,任务训练集可以作为少样本示例的来源,如果训练集足够大,那就可以为不同的任务输入选择不同的少样本示例。
具体来说,研究人员先利用text-embedding-ada-002模型为每个训练样本和测试样本生成向量表示。然后,对于每个测试样本,基于向量相似度,从训练样本中挑选出最相似的k个样本。
与微调方法相比,动态少样本选择利用了训练数据,但不需要对模型参数进行大量更新。
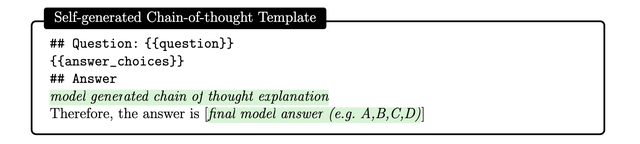
自生成思维链思维链(CoT)方法就是让模型一步一步思考,生成一系列中间推理步骤。
之前一种方法也是依赖专家手动编写少量的带有提示思维链的示例。

在这里,研究人员发现。可以简单地要求GPT-4使用以下提示为训练示例生成思维链:
但研究人员也指出这种自动生成的思维链可能包含错误的推理步骤,于是设置了一个验证标签作为过滤器,可以有效减少错误。
与在Med-PaLM 2模型中专家手工制作的思维链示例相比,GPT-4生成的思维链基本原理更长,而且分步推理逻辑更细粒度。
选项洗牌集成除此之外,GPT-4在做选择题时,可能会存在一种偏见,就是不管选项内容是什么,它会偏向总是选择A,或者总是选择B,这就是位置偏差。
为了减少这个问题,研究人员选择将原来的选项顺序打乱重排。比如原先选项是ABCD,可以变成BCDA、CDAB。
然后让GPT-4做多轮预测,每轮使用选项的一个不同排列顺序。如此一来“迫使”GPT-4考虑选项的内容。
最后对多轮预测结果做个投票,选择最一致、正确的选项。
将以上几种提示策略组合在一起就是Medprompt,下面来看测试结果。
多项测试最优在测试中,研究人员采用了MultiMed QA评估基准。
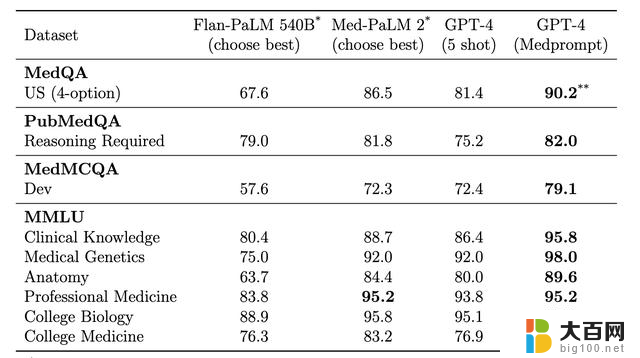
使用Medprompt提示策略的GPT-4,在MultiMedQA的九个基准数据集中均取得最高分,优于Flan-PaLM 540B、Med-PaLM 2。
此外研究人员还讨论了Medprompt策略在“Eyes-Off”数据上的表现,也就是在训练或优化过程中模型未曾见过的数据中的表现,用于检验模型是否过拟合训练数据。
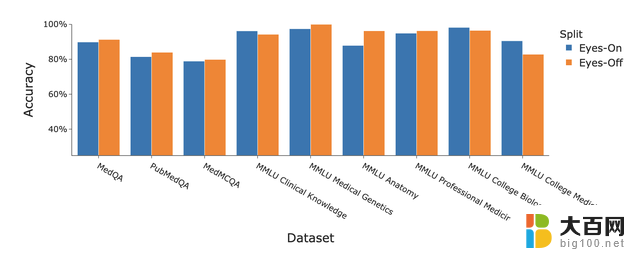
结果GPT-4结合Medprompt策略在多个医学基准数据集上表现出色,平均准确率达到了91.3%。
研究人员还在MedQA数据集上进行了消融实验,探索了三个组件对于整体性能的相对贡献。
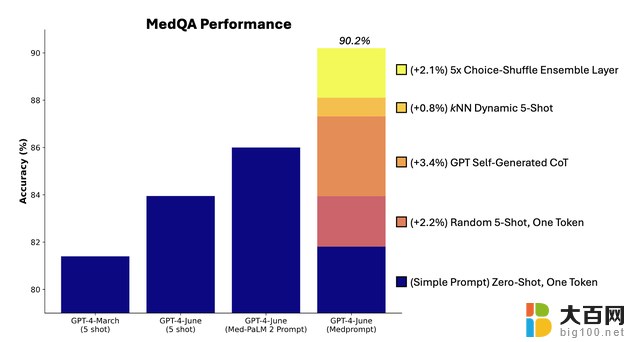
其中自动生成思维链步骤对性能提升的贡献最大。
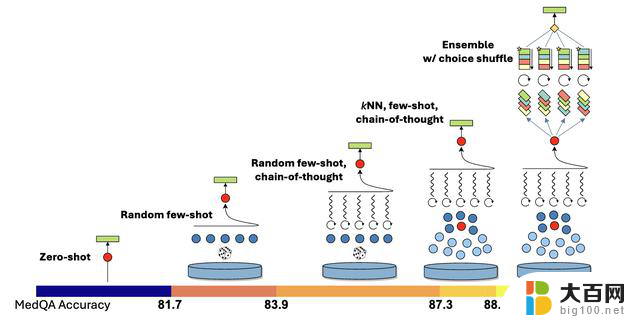
而且GPT-4自动生成的思维链比Med-PaLM 2中专家策划的得分更高:

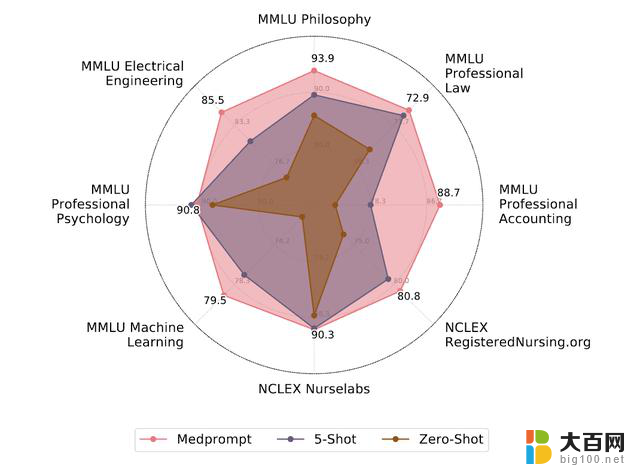
最后,研究人员还探索了Medprompt的跨域泛化能力。取用了MMLU基准中的六个不同的数据集,涵盖了电气工程、机器学习、哲学、专业会计、专业法律和专业心理学的问题。
还添加了另外两个包含NCLEX(美国护士执照考试)问题的数据集。
结果显示,Medprompt在这些数据集上的效果与在MultiMedQA医学数据集上的提升幅度相近,平均准确率提高了7.3%。
论文链接:https://arxiv.org/pdf/2311.16452.pdf
参考链接:
[1]https://twitter.com/erichorvitz/status/1729854235443884385
[2]https://twitter.com/emollick/status/1729733749657473327
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
微软提示工程开创新纪元:GPT-4成为医学专家,超越其他高度微调模型!相关教程
- 纳指跌超500点,微软跌逾6%,原油涨超2%,央行新工具落地,华为披露5859亿元,中美金融工作组第六次会议汇总
- AI助力苹果超越微软,成为全球市值最高公司的秘密揭秘
- AI引领微软超越苹果,全球市值之王的宝座再度易主
- 苹果或将放弃一年一更新模式,英伟达超越微软,纯血鸿蒙官宣10月8日开启公测极客头条
- 微软批准高达600亿美元股票回购,将季度股息提高10%,股东福利多多
- 微软逾110亿美元加持,AI赛道马力全开!- 引领人工智能技术创新的巨头
- 微软超越苹果,云计算与 AI 技术引领未来
- 微软和OpenAI提供1000万美元资助,助力媒体利用AI工具
- 微软与OpenAI计划投资1000亿美元开发AI超级计算机,将如何改变未来人工智能技术?
- 微软市值破3.12万亿美元,超过苹果成为全球最有价值公司
- 国产CPU厂商的未来较量:谁将主宰中国处理器市场?
- 显卡怎么设置才能提升游戏性能与画质:详细教程
- AMD,生产力的王者,到底选Intel还是AMD?心中已有答案
- 卸载NVIDIA驱动后会出现哪些问题和影响?解析及解决方案
- Windows的正确发音及其读音技巧解析:如何准确地发音Windows?
- 微软总裁:没去过中国的人,会误认为中国技术落后,实际情况是如何?
微软资讯推荐
- 1 显卡怎么设置才能提升游戏性能与画质:详细教程
- 2 ChatGPT桌面版:支持拍照识别和语音交流,微软Windows应用登陆
- 3 微软CEO称别做井底之蛙,中国科技不落后西方使人惊讶
- 4 如何全面评估显卡配置的性能与适用性?快速了解显卡性能评估方法
- 5 AMD宣布全球裁员4%!如何影响公司未来业务发展?
- 6 Windows 11:好用与否的深度探讨,值得升级吗?
- 7 Windows 11新功能曝光:引入PC能耗图表更直观,帮助用户更好地监控电脑能耗
- 8 2024年双十一七彩虹显卡选购攻略:光追DLSS加持,畅玩黑悟空
- 9 NVIDIA招聘EMC工程师,共同推动未来技术发展
- 10 Intel还是AMD游戏玩家怎么选 我来教你双11怎么选CPU:如何在双11选购适合游戏的处理器
win10系统推荐
系统教程推荐
- 1 win11文件批给所有权限 Win11共享文件夹操作详解
- 2 怎么清理win11更新文件 Win11清理Windows更新文件的实用技巧
- 3 win11内核隔离没有了 Win11 24H2版内存隔离功能怎么启用
- 4 win11浏览器不显示部分图片 Win11 24H2升级后图片无法打开怎么办
- 5 win11计算机如何添加常用文件夹 Win11文件夹共享的详细指南
- 6 win11管理应用权限 Win11/10以管理员身份运行程序的方法
- 7 win11文件夹内打开图片无预留 Win11 24H2升级后图片无法打开怎么办
- 8 win11访问另外一台电脑的共享文件夹 Win11轻松分享文件的方法
- 9 win11如何把通知关闭栏取消 win11右下角消息栏关闭步骤
- 10 win11安装更新0x800f081f Win11 23H2更新遇到错误代码0x800f081f怎么处理