除英伟达外,还有哪些厂商会采用Arm最强服务器CPU内核?
在不久前的Hot Chip 2023活动上,Arm披露了关于Neoverse V2的更多细节。目前英伟达(NVIDIA)应该是Neoverse V2平台的第一个客户。
除了英伟达之外,还有谁会采用Neoverse V2?
近年来,随着云计算及人工智能技术的快速发展,头部的大型服务器及云服务提供商都纷纷开始针对其工作负载大量定制或者设计各类处理器,但是设计一款好的处理器确实很困难,这也使得Arm面向云端的处理器IP大受欢迎。
据介绍,Neoverse V2 平台(代号“Demeter”)配备最新的 V 系列核心和产业广泛部署的 Arm CMN-700 mesh 互连技术。Neoverse V2 将为云和 HPC 工作负载提供市场领先的整型性能,并引入若干 Armv9 架构安全增强功能,是迄今为止 Arm 为服务器设计的最好的核心。
这也是为什么英伟达(NVIDIA)选择了Arm Neoverse V2内核及其他组件打造的72核的名为“Grace”服务器CPU,它是英伟达系统架构中不可或缺的一部分,可支持传统HPC仿真和建模工作负载的全CPU计算,并提供辅助内存和计算能力。凭借四个128位 SVE2 矢量引擎等,Demeter核心可以运行经典的 HPC 工作负载以及某些 AI 推理工作负载,甚至可能是在某些情况下重新训练人工智能模型。如果设计中可能有 16 到 256 个内核,那么触发器当然可以堆叠起来。

△NVIDIA Grace服务器CPU
除了英伟达之外还有谁会在他们的服务器CPU设计中使用 Neoverse V2平台?
AWS 很可能会在其未来的 Graviton4 服务器处理器中采用 Neoverse V2 ,并在其当前的 Graviton3 处理器中使用代号为“Zeus” 的Neoverse V1 内核。
目前尚不清楚谷歌在传闻中正在开发的两个定制 Arm 服务器芯片中使用了什么内核?传闻其中一个是与 Marvell 合作,另一个是自己的团队自研,很可能是使用了Neoverse V2内核。
Ampere Computing 已在其 192 核“Siryn”AmpereOne 芯片中从 Arm 的Neoverse N1 内核切换为自己的内核(我们称之为 A1)。
印度高级计算发展中心 (C-DAC) 正在为 HPC 工作负载构建自己的“Aum”处理器,它基于Arm的Neoverse V1核心。
富士通、Arm 和日本 RIKEN 实验室联合为“Fugaku”超级计算机使用的48 核 A64FX 处理器打造的定制 Arm 内核中的 512 位向量可以被视为一种Neoverse V0 核心在于 SVE 设计最初是为 A64FX 创建的。
阿里巴巴正在其自主研发的 128 核倚天710处理器中使用 代号为“Perseus”的Neoverse N2 核心,如果它认为需要在标准服务器中支持更多向量和矩阵数学。则可以在后续倚天芯片中切换到Neoverse V2 核心鉴于人工智能算法的使用越来越多,这些算法对此类数学运算的要求很高。此外,华为海思在其 64 核鲲鹏920服务器芯片中也采用了Arm的 Neoverse“Ares”N1 内核,出于同样的原因,它也对升级Neoverse V2核心有需求。
但是,根据Arm 正式向美国证券交易委员会正式递交IPO文件显示,Neoverse V系列处理器可能无法向阿里及华为等中国厂商提供授权。Arm称。“Neoverse 系列处理器中性能最高的处理器达到或超过了美国和英国出口管制制度下的性能阈值,从而在出口和交付给中国客户之前触发了出口许可证要求。” “鉴于对运往中国的 HPC 技术的国家安全担忧更高,而且政府的响应时间表尚未确定,获得此类出口许可证可能具有挑战性且不可预测。”
Neoverse V2详解:IPC性能提升了13%,拥有4个128位SVE2矢量引擎
Arm 于 2020 年 9 月将其 Neoverse 核心和 CPU 设计分为三个系列,分别为V系列高性能核心(具有双倍向量引擎)、N系列核心(专注于整数性能)、 E系列核心(入门级,重点关注能源效率和边缘的芯片)。近几年来,该路线图已经扩展和更新了很多次,最新的路线图(带有 N2 平台添加的 CSS 子系统变体)已在 Hot Chips 上展示:
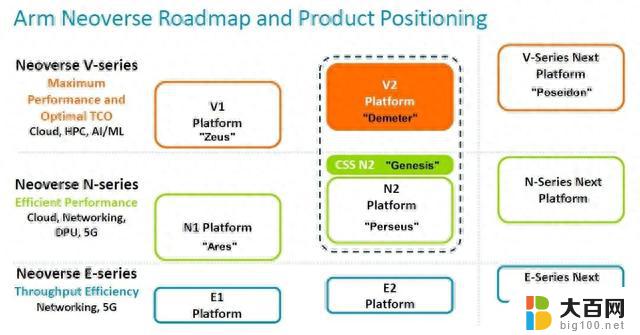
Arm 院士兼首席 CPU 架构师 Magnus Bruce 在 Hot Chips 上介绍了 V2 平台,谈论了该架构以及与 V1 平台相比的变化。下面这张图表很好地总结了这一点:
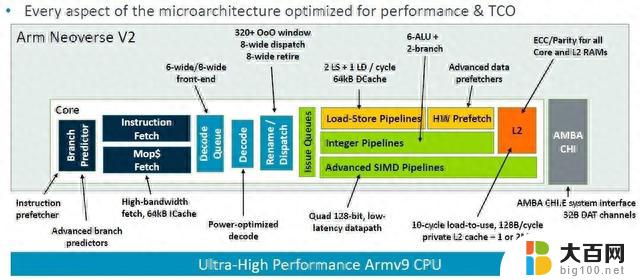
“这个管道的基础是一个预运行分支预测器,这个分支预测器充当指令预取器,它将提取与分支解耦。”Magnus Bruce 解释道:“大型分支预测结构可以覆盖非常大的实际服务器工作负载。我们使用在发布后读取的物理寄存器文件,允许非常大的发射队列,而无需存储数据。这对于解锁ILP(指令级并行性)是必要的。我们使用低延迟和专用L2缓存、具有最先进的预取算法的低延迟L1和专用L2高速缓存以及积极的存储-加载转发,以保持内核具有最小的气泡和停滞。来自系统的动态反馈机制允许核心调节攻击性并主动防止系统拥塞。这些基本概念使我们能够提高机器的宽度和深度,同时保持快速预测失误恢复所需的短管道。”
重要的是,V2是基于新的Armv9指令集的实现,旨在颠覆该架构,与十多年来定义Arm芯片的许多代Armv8架构相比,它带来了性能、安全性和可扩展性的增强。
V2芯片的架构调整是微妙的,但显然是有效的。但同样明显的是,其13%的性能改进与Arm早在2019年就设定的30%的每时钟指令性能(IPC)改进目标相去甚远:
下面是对 V2 核心的分支预测器和获取单元以及 L1 缓存的深入分析:

正如您所看到的,V1 核心的很多功能都被延续到了 V2 核心,但 V2 核心也有一些更新。许多队列、表和带宽都增加了一倍,但微操作缓存实际上在转向 V2 设计时减少了。根据使用芯片模拟器为 V1 和 V2 建模的 SPEC CPU 2017 整数基准,对 V2 内核的调整使每个时钟指令增加了约 2.9%。
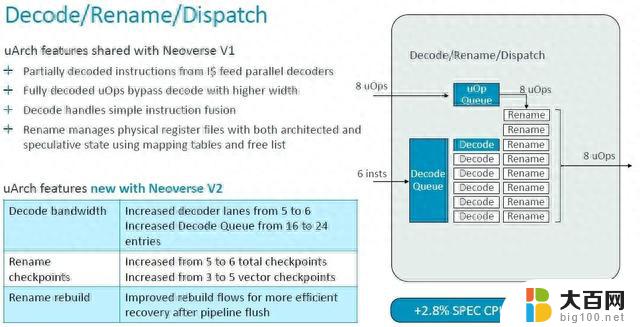
同时,V1 内核在解码和指令分派方面的一些微架构优点直接传递到 V2 内核,但解码器通道和队列有所提升。总体效果是 IPC 提高了 2.9%,这也是通过 SPEC CPU 2017 整数测试来衡量的。(IPC 通常是使用混合测试来计算的,而不仅仅是 SPEC CPU 评级。)
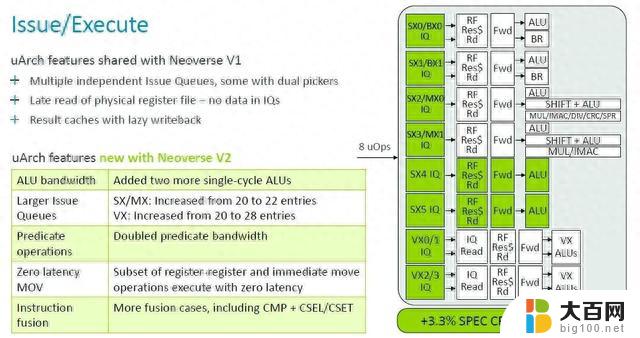
借助 V2 内核,Arm 架构师又添加了两个单周期算术逻辑单元 (ALU),并增加了问题队列的大小,并将谓词运算符的带宽加倍,这些调整加上其他一些调整,又增加了 3.3%核心性能在 2.8 GHz 主频下归一化。
与 V1 核心一样,V2 核心有两个加载/存储管道和一个加载管道,但表后备缓冲区 (TLB) 上的条目增加了——从 40 个条目增加到 48 个条目——并且各种存储和读取队列也增加了变得更大。

这一变化和其他变化使 V2 核心性能又增加了 3%。
Arm 架构师通过硬件预取数据的变化获得了最大的性能提升:
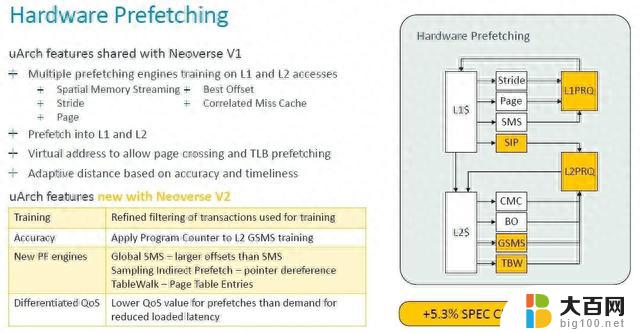
“Neoverse V1已经具备了最先进的预取功能。”Bruce解释道:“我们的预取器使用针对L1和L2未命中的多个引擎进行训练,并预取到L1和L2缓存中,通常使用虚拟地址来允许页面交叉,这使它们也可以充当TLB预取器。预取器利用来自互连的动态反馈,以及CPU内的准确性和及时性测量来调节其攻击性通过改进训练,通过更好的滤波和训练操作来提高准确性,并在更多的预取器中使用程序计数器,以实现更好的相关性和更好的混叠预防。同时还添加了新的预取引擎。L2获得了全局空间内存流引擎,这增加了它可以覆盖的预取器的偏移范围,并且它比旧的标准SMS引擎有了很大的改进。我们添加了一个采样间接预取器,用于处理指针取消引用场景。这不是数据预测,而是学习数据消耗模式,作为其他负载的指针。我们还添加了一个表遍历预取器,它可以将页表条目预取到二级缓存中。现在,所有这些添加的预取器及其攻击性都会在系统中造成拥塞。特别是在共享资源,如系统级高速缓存或DRAM。我们为需求和预取提供不同的QoS级别。这使我们能够在不影响需求请求的加载延迟的情况下进行积极的预取。动态预取动态反馈将预取器的攻击性调节到可持续的水平。这些变化加在一起使规范管理器增加了5.3%,但更重要的是,我们同时看到SLC未命中率减少了8.2%,因此我们可以用更少的DRAM流量获得更高的性能。”
以下是二级缓存如何发挥其魔力:
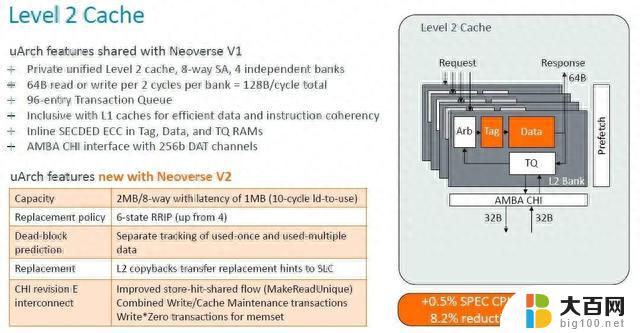
二级缓存加倍对性能来说并没有太大变化,但系统级缓存未命中的减少确实间接提高了性能。
以下是V2的 IPC 的总和:
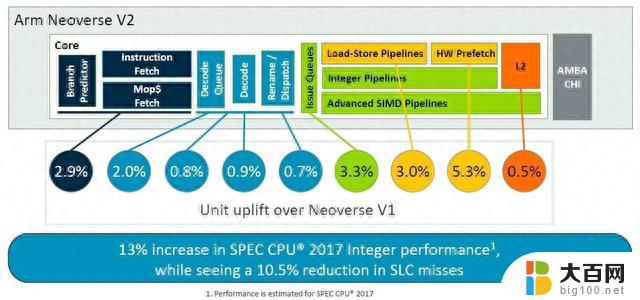
这些是加法效应,而不是乘法效应,V2 核心的整数性能提高了 13%——这也是经过建模的,而且这只是使用 SPEC CPU 2017 整数测试——同时将系统级缓存缺失减少了 10.5%总体百分比。
每当新的核心或芯片问世时,该核心或芯片都会根据性能、功耗和面积的相互作用进行分级。以下是 V1 和 V2 核心的堆叠方式:
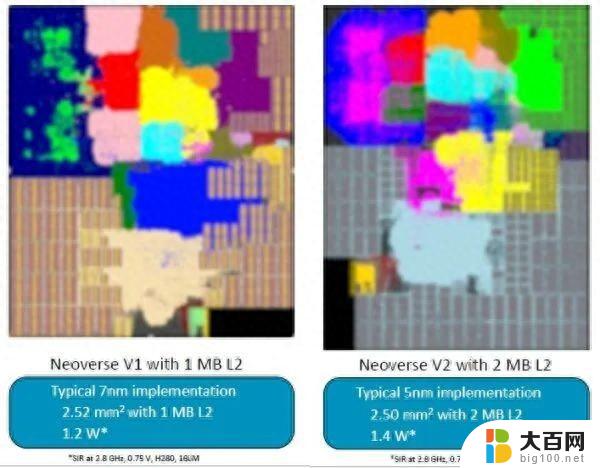
采用7nm工艺实现的 V1 核心面积为 2.5 平方毫米,L2缓存为 1 MB,功耗约为 1.2 瓦。V2 核心的面积稍小一些,L2 缓存是 2 MB,功耗提高了 17%。这些比较均以 2.8 GHz 时钟速度进行标准化。
当然,V2 不仅仅是一个核心,而是一个可以授权的平台规范:
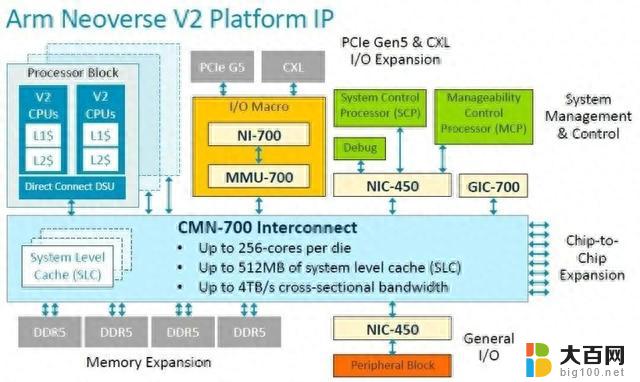
借助 CMN-700 互连,被许可厂商可以构建可扩展至 256 个内核和 512 MB 系统级缓存的 V2 CPU,该互连可在所有内核、内存和内存中提供 4 TB/秒的横截面带宽及位于网格上的 I/O 控制器。
V2 核心的很多演示都集中在整数方面,但在演讲的问答中,Bruce 确实说了一些关于矢量性能的有趣内容。V1 核心有一对 256 位 SVE1 矢量引擎,但 V2 核心有四个 128 位 SVE2 矢量引擎。正如Bruce所说,这样做是因为将混合精度数学分散到四个单元比尝试分散到两个单元更容易(而且我们认为更有效)。
但正如我们所说,除了英伟达和可能的 AWS 之外,谁将获得 V2 核心的许可?也许任何打算使用 V2 的人都已经在进行自定义设计。
编辑:芯智讯-浪客剑 来源:The next platform
除英伟达外,还有哪些厂商会采用Arm最强服务器CPU内核?相关教程
- 英伟达:压轴靓仔的压力 - 如何应对厂商的挑战?
- 英伟达新赛道:首款Arm消费级高端CPU被曝2025年登场,Arm处理器首次进军高端消费市场
- 华为成英伟达最强对手,外媒爆料华为没有料到的消息
- 英伟达H20新GPU芯片预计2024年上市,国产厂商联手备战,内存市场迎涨价潮
- 微软和OpenAI展示最新英伟达服务器,以色列防长行程延迟 - 环球市场报道
- 人工智能芯片竞争加剧,英伟达还“有戏”吗?- 英伟达在人工智能芯片市场的竞争地位如何?
- 英伟达被曝入局PC端CPU!网友:眼馋苹果M1打开市场,英伟达PC端CPU即将挑战苹果M1的垄断地位!
- 英伟达新产品规划曝光,两年12款GPU在路上|最前线:全面解读英伟达最新GPU产品规划
- 2023年全球十大芯片设计厂商排名揭晓:英伟达荣登榜首,韦尔半导体跻身前十!
- 英伟达一季报要来了!这一次,动静不会小?英伟达一季度财报即将发布,市场预期巨大!
- 国产CPU厂商的未来较量:谁将主宰中国处理器市场?
- 显卡怎么设置才能提升游戏性能与画质:详细教程
- AMD,生产力的王者,到底选Intel还是AMD?心中已有答案
- 卸载NVIDIA驱动后会出现哪些问题和影响?解析及解决方案
- Windows的正确发音及其读音技巧解析:如何准确地发音Windows?
- 微软总裁:没去过中国的人,会误认为中国技术落后,实际情况是如何?
微软资讯推荐
- 1 显卡怎么设置才能提升游戏性能与画质:详细教程
- 2 ChatGPT桌面版:支持拍照识别和语音交流,微软Windows应用登陆
- 3 微软CEO称别做井底之蛙,中国科技不落后西方使人惊讶
- 4 如何全面评估显卡配置的性能与适用性?快速了解显卡性能评估方法
- 5 AMD宣布全球裁员4%!如何影响公司未来业务发展?
- 6 Windows 11:好用与否的深度探讨,值得升级吗?
- 7 Windows 11新功能曝光:引入PC能耗图表更直观,帮助用户更好地监控电脑能耗
- 8 2024年双十一七彩虹显卡选购攻略:光追DLSS加持,畅玩黑悟空
- 9 NVIDIA招聘EMC工程师,共同推动未来技术发展
- 10 Intel还是AMD游戏玩家怎么选 我来教你双11怎么选CPU:如何在双11选购适合游戏的处理器
win10系统推荐
系统教程推荐
- 1 win11文件批给所有权限 Win11共享文件夹操作详解
- 2 怎么清理win11更新文件 Win11清理Windows更新文件的实用技巧
- 3 win11内核隔离没有了 Win11 24H2版内存隔离功能怎么启用
- 4 win11浏览器不显示部分图片 Win11 24H2升级后图片无法打开怎么办
- 5 win11计算机如何添加常用文件夹 Win11文件夹共享的详细指南
- 6 win11管理应用权限 Win11/10以管理员身份运行程序的方法
- 7 win11文件夹内打开图片无预留 Win11 24H2升级后图片无法打开怎么办
- 8 win11访问另外一台电脑的共享文件夹 Win11轻松分享文件的方法
- 9 win11如何把通知关闭栏取消 win11右下角消息栏关闭步骤
- 10 win11安装更新0x800f081f Win11 23H2更新遇到错误代码0x800f081f怎么处理