机器人轻松模仿人类,微软新研究揭秘泛化到不同任务和智能体
IGOR团队 投稿
量子位 | 公众号 QbitAI
让机械臂模仿人类动作的新方法来了,不怕缺高质量机器人数据的那种。
微软提出图像目标表示(IGOR,Image-GOal Representation),“投喂”模型人类与现实世界的交互数据。
IGOR能直接为人类和机器人学习一个统一的动作表示空间,实现跨任务和智能体的知识迁移以及下游任务效果的提升。
要知道,在训练具身智能领域的基础模型时,高质量带有标签的机器人数据是保证模型质量的关键,而直接采集机器人数据成本较高。
考虑到互联网视频数据中也展示了丰富的人类活动,包括人类是如何与现实世界中的各种物体进行交互的,由此来自微软的研究团队提出了IGOR。

究竟怎样才能学到人类和机器人统一的动作表示呢?
IGOR框架解读IGOR框架如下所示,包含三个基础模型:
Latent Action Model、Policy Model和World Model。
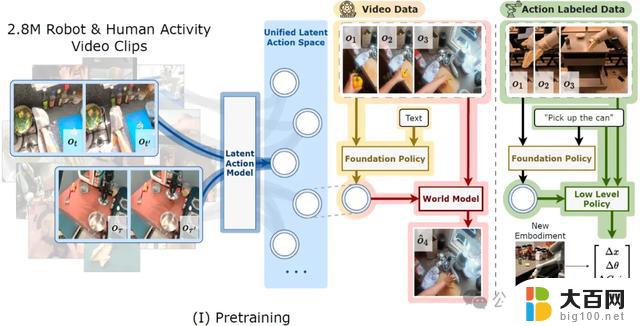
具体来说,IGOR先是提出了潜在动作模型LAM(Latent Action Model),将初始状态和目标状态之间的视觉变化压缩为低维向量,并通过最小化初始状态和动作向量对目标状态的重建损失来进行训练。
这样一来,具有相似视觉变化的图像状态将具有相似的动作向量,代表了他们在语义空间而非像素空间上的变化。
通过LAM,可以将互联网规模的视频数据转化为带有潜在动作标注的数据,大大扩展了具身智能基础模型能够使用的数据量。
这个统一的潜在动作空间使团队能够在几乎任意由机器人和人类执行的任务上训练Policy Model和World Model。
通过结合LAM和World Model,IGOR成功地将一个视频中的物体运动“迁移”到其他视频中。并且,这些动作实现了跨任务和跨智能体的迁移。
也就是说,用人的行为给机器人做演示,机器人也能做出正确的动作。如下图所示,LAM得到的潜在动作表示可以同时实现跨任务(用手移动不同物体)和跨智能体(用手的移动指导机械臂的移动)的迁移。


△Latent Action实现跨任务和智能体的迁移
以下是模型架构的具体细节。
Latent Action ModelLAM的目标是以无监督的方式从互联网规模的视频数据中学习和标注潜在动作,即给定视频帧序列,对于每一对相邻帧提取潜在动作表示。
为此,LAM模型由一个Inverse Dynamic Model(IDM)和Forward Dynamic Model(FDM)组成。
IDM的从视频帧序列中提取潜在动作表示,而FDM负责用学到的表示和当前视频帧来重建接下来的视频帧。
由于将潜在动作表示限定在较低的维度,因此LAM模型会将两帧之间语义上的区别学习到之中。
值得注意的是,这种方式天然保证了学到的潜在动作是具有泛化性的。
如下图所示, 在未见数据集上,LAM学到的相似潜在动作反映了相似的语义,包括打开夹子、机械臂向左移动和关闭夹子,这些潜在动作在不同任务间共享,进而提升下游模型的泛化性。

△Latent Action Model在未见数据集上的表现
Foundation World ModelWorld Model的作用是根据历史视频帧和未来多帧的潜在动作表示,生成在历史帧的基础上执行各个潜在动作之后的未来视频帧。
为此,研究人员选择从预训练的视频生成模型上进行微调,将条件从文本换成了潜在动作表示和FDM的重建输出。
在具身智能的相关数据集上进行微调之后,研究人员观察到World Model可以成功地在给定相同历史帧时,针对不同的潜在动作表示生成相对应的未来视频帧。
如下图所示,此方法可以通过潜在动作和World Model控制不同物体的独立移动。
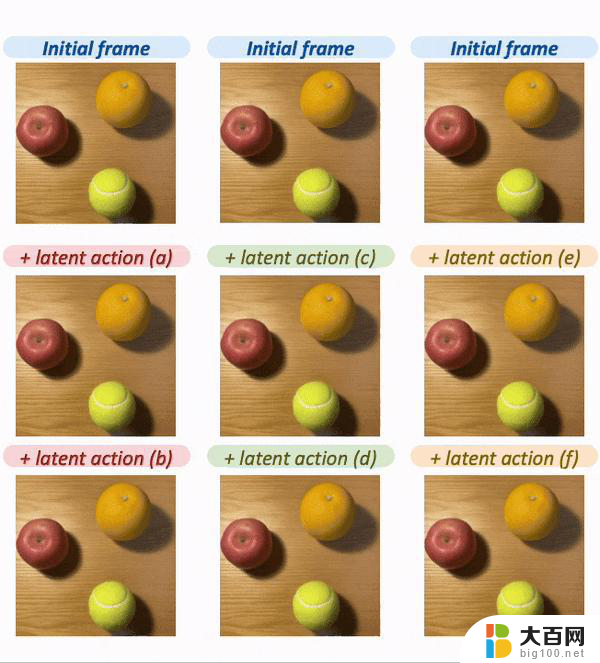
△World Model对于给定的不同潜在动作表示时的生成结果
Foundation Policy ModelPolicy Model的目标是在具体的下游任务上,根据视频帧和文本指令来预测智能体每一步要采取的动作。
在IGOR中,它的训练分为了两个阶段。
在第一阶段,Policy Model将根据输入的视频帧和文本指令来预测LAM提取出的相应的潜在运动表示,从而建立从视频帧到通用潜在运动表示的映射。
在第二阶段,该模型则会根据文本指令、视频帧以及第一阶段模型预测出来的潜在动作表示共同预测下游任务上具体的运动标签。
和现有模型相比,第一阶段预测出的潜在动作表示蕴含了完成该任务需要达成的短期目标,丰富了模型的输入信息,因此提升了最终策略的任务成功率,如下图所示。
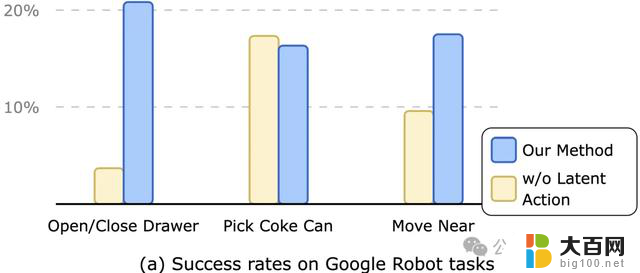
△Policy Model在下游机器人任务上的表现
在相同的场景下给定不同的文本指令,研究人员也验证了Policy Model的有效性,即模型可以根据不同的指令生成相应的潜在动作表示,进而通过World Model模拟执行相应的指令。

△Policy Model和World Model对于不同文本指令的生成结果
总的来说,IGOR提出了通过大量人类和机器人视频预训练学习动作表示并泛化到不同任务和智能体的新方法。通过从大量视频中学到的动作表示,IGOR可以实现机器人轻松模仿人类动作,进而实现更通用的智能体。
项目主页:https://aka.ms/project-igor
论文:https://aka.ms/project-igor-paper
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
机器人轻松模仿人类,微软新研究揭秘泛化到不同任务和智能体相关教程
- 微软人工智能新闻聚合:假新闻和嘲笑逝者问题曝光
- 微软CEO纳德拉:大规模投资人工智能基础设施
- Meta开发人工智能搜索引擎,减少对谷歌和微软的依赖
- CPU性能与价格的关系揭秘:1万块钱的CPU到底有多强?内行人揭秘真相
- 微软与AMD共同推动AI在PC上的应用,助力智能化未来
- 微软Win11 Canary 26257预览:全新文件管理器和鼠标体验优化
- 微软将推出全新Windows AI功能,助力操作系统智能化升级
- 微软中国员工如何实现自己和家人变美国人的梦想?
- 微软逾110亿美元加持,AI赛道马力全开!- 引领人工智能技术创新的巨头
- Nvidia首席执行官表示人工智能将在5年内与人类竞争:AI技术发展迅猛
- 国产CPU厂商的未来较量:谁将主宰中国处理器市场?
- 显卡怎么设置才能提升游戏性能与画质:详细教程
- AMD,生产力的王者,到底选Intel还是AMD?心中已有答案
- 卸载NVIDIA驱动后会出现哪些问题和影响?解析及解决方案
- Windows的正确发音及其读音技巧解析:如何准确地发音Windows?
- 微软总裁:没去过中国的人,会误认为中国技术落后,实际情况是如何?
微软资讯推荐
- 1 显卡怎么设置才能提升游戏性能与画质:详细教程
- 2 ChatGPT桌面版:支持拍照识别和语音交流,微软Windows应用登陆
- 3 微软CEO称别做井底之蛙,中国科技不落后西方使人惊讶
- 4 如何全面评估显卡配置的性能与适用性?快速了解显卡性能评估方法
- 5 AMD宣布全球裁员4%!如何影响公司未来业务发展?
- 6 Windows 11:好用与否的深度探讨,值得升级吗?
- 7 Windows 11新功能曝光:引入PC能耗图表更直观,帮助用户更好地监控电脑能耗
- 8 2024年双十一七彩虹显卡选购攻略:光追DLSS加持,畅玩黑悟空
- 9 NVIDIA招聘EMC工程师,共同推动未来技术发展
- 10 Intel还是AMD游戏玩家怎么选 我来教你双11怎么选CPU:如何在双11选购适合游戏的处理器
win10系统推荐
系统教程推荐
- 1 win11文件批给所有权限 Win11共享文件夹操作详解
- 2 怎么清理win11更新文件 Win11清理Windows更新文件的实用技巧
- 3 win11内核隔离没有了 Win11 24H2版内存隔离功能怎么启用
- 4 win11浏览器不显示部分图片 Win11 24H2升级后图片无法打开怎么办
- 5 win11计算机如何添加常用文件夹 Win11文件夹共享的详细指南
- 6 win11管理应用权限 Win11/10以管理员身份运行程序的方法
- 7 win11文件夹内打开图片无预留 Win11 24H2升级后图片无法打开怎么办
- 8 win11访问另外一台电脑的共享文件夹 Win11轻松分享文件的方法
- 9 win11如何把通知关闭栏取消 win11右下角消息栏关闭步骤
- 10 win11安装更新0x800f081f Win11 23H2更新遇到错误代码0x800f081f怎么处理